

 青木です。paizaラーニング担当のエンジニアです。
青木です。paizaラーニング担当のエンジニアです。
プログラミングの多様な練習問題を公開している「レベルアップ問題集」に、「巡回セールスマン問題メニュー」を追加しました!
この「巡回セールスマン問題」、アルゴリズムを勉強したことがある方は耳にしたことがあるかもしれません。競技プログラミングでも定番の問題となっています。
今回は、「巡回セールスマン問題」とはそもそもどんなものなのか?から始まり、解法や実際の問題の解き方まで詳しく解説していきたいと思います。
自分のプログラミングのスキルを一段引き上げたい方はぜひ一緒に取り組んでいきましょう。プログラミング初心者の方は、少し難しく感じるかもしれませんが、まずは概念だけでも理解してみてください。
「巡回セールスマン問題」とは
巡回セールスマン問題とは、都市の集合と各都市間の距離が与えられた状態で、ある都市からスタートしてすべての都市を一度ずつ訪れたのち、最後に出発した都市に戻ってくるような経路(これを巡回路と呼びます)のうち、もっともその長さが短いものを求める問題です。

paizaラーニング「アルゴリズム入門編:「巡回セールスマン問題」を学ぶ」より
営業のセールスマンが複数の会社を好きな順番で営業訪問するとき、総移動距離がなるべく短くなるよう訪問する順番を工夫することを考えるとイメージしやすいかと思います。
この問題は最適化の分野で盛んに研究されている問題で、英語では「Traveling Salesman Problem」(もしくは、この頭文字を取って「TSP」) と呼ばれています。
もう少し突っ込んだ話をすると、TSPはNP困難という複雑性クラスに属しており、効率よく(=問題サイズの多項式時間で)解くことがほとんどできない問題だろうとされています。このあたりはしっかり理解するには結構ハードルが高いので、初耳の方は「そうなんだ~」と思っておけば大丈夫です。
これまでにTSPを解くさまざまな解法が提案されており、「巡回セールスマン問題メニュー」では大きく分けて3ジャンル8種類の解法を扱っています。
解法について
1. 厳密解法
厳密解法は、問題を厳密に解く、つまり最適解を出力する解法になります。
グラフの頂点数が少ないときはこの厳密解法でTSPを解くことが可能ですが、頂点数が多くなるにつれ実行時間が爆発的に大きくなってしまうため、注意が必要です。
巡回セールスマン問題メニューでは、「順列全列挙による解法」「動的計画法」の2種類を学習することができます。
2. 近似解法
近似解法は、最適解ではないものの、近似解と呼ばれる、精度がある程度よい解を出力する解法です。
近似解とは、実行可能解(かつ問題の何らかの制約を満たす解)ではあるが、正解(厳密解)ではないものを言う。これは組み合わせ最適化問題の正解(すなわち最適解)であることが(厳密には)保証されないところの解を得るものである。
厳密解法に比べると解の精度は劣りますが、頂点数が多くなっても高速に動作するため、ある程度大きなグラフに対しても適用することができます。巡回セールスマン問題メニューでは、「2-近似アルゴリズム」を学習することができます。
3. 発見的解法(ヒューリスティクス)
発見的解法(ヒューリスティクス)は考察や経験則に基づく直感的なアプローチで、解の精度がまったく保証されないものの、ある程度よい解が出力されることが期待される解法です。
巡回セールスマン問題メニューでは、「最近傍法」「貪欲法」「2-opt法」「禁断探索法」「焼きなまし法」を学習することができます。
問題集は、各解法を理解するために必要な概念を1問ずつていねいに解説しているため、知識が十分ではない方でも気軽に取り組めるようになっています。
ここからは巡回セールスマン問題メニューが扱っている8種類の解法について、大まかにPythonのコードを用いて解説していきます。
なお、Pythonの基本は「Python3入門編」(全編無料)で学習できます。Pythonは初めてという方は、さきに基礎文法などを身につけておくとスムーズに理解できるかもしれません。

問題に取り組む前の前提知識
内容に入る前に、巡回セールスマン問題メニューの決まりごとや、解くにあたって必要な知識を簡単に整理します。なお、各用語や概念について詳しく知りたい方は適宜Web検索してみてください。
頂点とそれらをつなぐ辺の集まりのことをグラフといいます。特に、任意の頂点の間に辺が存在するようなグラフのことを、完全グラフと呼びます。
頂点の列で、隣り合う頂点の間に辺が存在しているもののことを、そのグラフのパス(道)といいます。始点と終点が一致しているパスで、始点以外に頂点の重複がないものをサイクル(閉道)と呼びます。グラフの全頂点を含むサイクルを巡回路と呼びます。
巡回セールスマン問題メニューでは、各都市は二次元平面上の点とします。また、任意の2都市の間に辺が存在するとします。つまり、この問題集で扱うグラフは都市を頂点集合とする完全グラフです。ある都市とある都市を結ぶ辺の長さは、都市間のユークリッド距離とします。都市 (x_1, y_1) と都市 (x_2, y_2) のユークリッド距離は、√((x_1-x_2)^2 + (y_1-y_2)^2) です。
各都市には 0 または 1 から始まる連番の番号がついており、都市 1、都市 2、、、、のように呼びます。
巡回路は都市番号の順列で表現します。例えば、5つの都市 (都市 0, 都市 1, 都市 2, 都市 3, 都市 4) をめぐる巡回路 0 -> 2 -> 3 -> 4 -> 1 -> 0 は、順列 [0, 2, 3, 4, 1] で表現します。
特にことわりがない限り、
n = 都市の数 (グラフの頂点数) を表す整数
points = 入力された n 個の都市の座標が格納された配列
とします。
では、さっそく最初の解法から見ていきましょう。
巡回セールスマン問題を解いてみよう!
以降で示す問題は、問題名にリンクをしており、遷移先ページで問題内容や条件の詳細が確認できます。ブラウザ上でコードを書いて実行、正否の判定までおこなえます。
また、「○ランク相当」という表記は、paizaのスキルチェックでどのランクに相当するかを示しています。ランクごとのレベル感など、スキルチェックについて詳しくはこちらをごらんください。
順列全列挙(Bランク相当)
巡回セールスマン問題メニューで最初に扱うのは、厳密解法のひとつである「順列全列挙による解法」です。
これは、巡回路を全列挙し、各巡回路についてその長さ(巡回路長)を計算して、もっとも巡回路長が短いものを答えとする解法です。TSPを解こうと思った際に多くの人がまず最初に思いつく、一番素朴なアルゴリズムではないでしょうか。
前提知識のところで述べた通り、巡回路と順列は1対1対応しているとみなすことができますから、順列が全列挙できれば巡回路を全列挙できたことになります。
順列を簡単におさらいしておくと、順列とは集合の要素の並べ方であり、{1, 2, 3} の順列は
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1
の6通りです。
このアルゴリズムは、順列を全列挙するアルゴリズムが理解できればすぐに実装できます。言語によっては標準ライブラリに順列を全列挙する関数が用意されていることもありますが、ここでは自力で順列を全列挙する再帰関数を書きます。
def permutations(n, p): if len(p) == n: print(p) return for i in range(1, n + 1): if i in p: continue p.append(i) permutations(n, p) del p[-1]
ちなみに「再帰関数って?」となった方は以下の記事も参考にしてください。
(参考)【Python】再帰関数を使ったプログラミング問題の解き方を解説する - paiza times
permutations(n, [])を呼び出すと、{1, 2, ..., n} の順列を全列挙することができます。
最初の if ブロックは順列 p を出力しているだけで、重要なのは for ループの処理です。ここでは、p にまだ含まれていない要素を 1 つ見つけてそれを p の末尾に付け加えたのち自分自身を再帰で呼び出し、戻って来たら p の末尾を削除するという処理をしています。このようにすることで、{1, 2, ..., n} の順列をすべて求めることができます。
このようにして求めた各順列に対して、対応する巡回路の巡回路長を計算すれば、TSPを解くことができます。ただしこの解法は時間計算量が O(n!) であるため、都市の個数が 2 桁以上になると実行時間がとても長くなってしまいます。
動的計画法(Aランク相当)
次に扱うのは、動的計画法です。これも順列全列挙と同じく問題を厳密に解く厳密解法ですが、順列全列挙よりも計算効率がよいのが特徴です。
動的計画法は、一言で言うと「問題を部分問題に分割し、部分問題の答えを記録しながら、それらを利用することによって元の問題の答えを得る手法」です。動的計画法について詳しく学びたい方は、レベルアップ問題集「DPメニュー」に取り組んでみてください。また、以下の記事でも詳しく解説しています。
TSPを部分問題に分割することを考えてみます。ある都市 s からスタートして、集合 S に含まれるすべての都市を訪れ、都市 j に到達する最短路を p(j, S)、その長さを d(j, S) とおきます。
まず、簡単に分かることとして d(j, {j}) = (都市 s から都市 j までの距離) が挙げられます。
次に、p(j, S) において j の直前に訪れる頂点を i とします。すると、p(j, S) の頂点 i に到達するまでの部分路は、都市 s からスタートして集合 S - {j} に含まれるすべての都市を訪れ、頂点 i に到達する最短路になっているはずです。従って、d(j, S) は d(i, S - {j}) + (都市 i から都市 j までの距離) (ただし i は S - {j} に含まれる都市) の最小値となっていなければなりません。
TSPの答えは、d(s, {0, 1, ... , n-1}) です。これを求めるには、集合 S のサイズが 1 のもの d(0, {0}), d(1, {1}), ... , d(n-1, {n-1}) からスタートして、上の考察に基づいて S のサイズを 1 つずつ大きくしていけばよいでしょう。
上の動的計画法を実装したのが以下のコードです。
def dynamic_programming(n, points): d = [[2 ** 30 for b in range(2 ** n)] for i in range(n)] for i in range(n): d[i][2 ** i] = dist(points[0], points[i]) for b in range(2 ** n): for i in range(n): if b >> i & 1 == 0: continue for j in range(n): if b >> j & 1 == 1: continue tmp = d[i][b] + dist(points[i], points[j]) if tmp < d[j][b | 2 ** j]: d[j][b | 2 ** j] = tmp return d[0][2 ** n - 1]
distは都市を 2 つ受け取り距離を返す関数です。d は二次元配列で、d[i][b] = d(i, S)(b は S のビット列による表現)を満たします。集合のビット列による表現については、こちらの問題をご参照ください。
最初の for ループでは集合のサイズが 1 の場合について計算しており、次の for ループで集合のサイズを 1 つずつ増やしながら計算を行なっています。
この解法の時間計算量は O(n^2 2^n) です。
近似(Aランク相当)
これまでに扱ったふたつのアルゴリズムは常に最適解を求めることができますが、都市の数が多くなると計算に時間がかかりすぎるという欠点があります。
都市の数が多い問題に対しても現実的な時間で答えを出すためには、解の精度をある程度諦めなければなりません。
そこで、次に扱うのは2-近似アルゴリズムです。これは近似解法と呼ばれるもので、厳密に一番良い解(最適解)ではないものの、ある程度良い解(近似解)を求めることができます。2-近似という名の通り、このアルゴリズムは最悪でも最適値の2倍以下の値を持つ解を出力します。
2-近似アルゴリズムは、以下のようなアルゴリズムです。
- 都市をグラフの頂点とみなし、最小全域木 MST を求める
- MST の辺を複製して二重にしたグラフを作り、一筆書きをする
- 一筆書きにおいて訪れる都市を先頭から順に並べる。ただし、すでに訪れた都市には再度訪れないようにして、全都市をちょうど 1 度ずつ訪れる経路(巡回路)を作る
図で見るともっとイメージしやすいと思います。
最小全域木を求めて、

辺を複製して二重にしたグラフを作り、
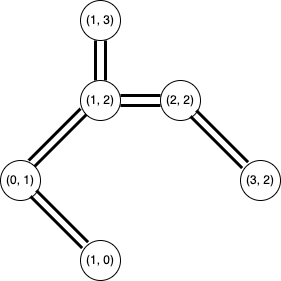
都市 (1,3) を始点として一筆書きをします。

この一筆書きをもとにして、巡回路を作ります。

これが、2-近似アルゴリズムの出力です。
最小全域木を求めるには、クラスカル法を用いるのがおすすめです。クラスカル法は、以下のようなアルゴリズムです。
- 都市を頂点とし、辺を 1 本も含まないグラフ G を用意する
- 都市のペアを結ぶ辺を全て列挙し、E とする
- E が空になるまで、以下を繰り返す
- E に含まれる辺のうち最も長さが短いものを E から削除して e とする
- e が結ぶ 2 つの都市が異なる連結成分に含まれているなら、G に e を追加する
- G を最小全域木として出力する
巡回セールスマン問題メニューでは、まず最小全域木を求める問題を解いてから 2-近似アルゴリズムを実装します。
最近傍法(Bランク相当)
ここからは、発見的解法(ヒューリスティクス)を扱います。ある程度よい解が出力されることが期待されるものの、解の精度がまったく保証されない解法です。
最近傍法は、始点となる都市を適当に 1 つ選び、今いる都市にもっとも近い都市を訪れることを繰り返すことによって巡回路を求める解法です。
これまでに扱ってきた解法と比べると遥かにシンプルで実装しやすいものとなっていますが、この解法は前述の通り解の精度がまったく保証されません。運よく最適解に近い解を出力することもあれば、全然精度のよくない解が出力されることもあるため、注意が必要です。
貪欲法(Aランク相当)
貪欲法は、なるべく短い辺をたくさん使って巡回路を作ろうというアプローチに基づくアルゴリズムです。概要を以下に示します。
- 都市を頂点とし、辺を 1 本も含まないグラフ G を用意する
- 都市のペアを結ぶ辺を全て列挙し、E とする
- E が空になるまで、以下を繰り返す
- E に含まれる辺のうち最も長さが短いものを E から削除して e とする
- G に e を追加したグラフを G' とする。G' のすべての頂点の次数が 2 以下かつ G' に閉路が存在しないなら、G を G' で更新する
- この時点で G は全都市を結ぶ一本のパスになっている (次数 1 の都市がただ 2 つ存在する) ため、その始点と終点を辺で繋いで巡回路を作る
「G' のすべての頂点の次数が 2 以下かつ G' に閉路が存在しないなら、G を G' で更新する」という部分が少し分かりにくいかもしれないので補足します。
ここでは、頂点を結ぶ 1 本道を作ろうとしています。グラフ G' が一本道であるためには、まず閉路が存在してはいけません。閉路とは、始点と終点が等しい経路のことで、要するに輪っかのような経路のことです。
そして、1 本道であるためには道が分岐していてはいけないので、各頂点に接続している頂点の個数は 2 以下でなければいけません。
G' に閉路が存在するか、つまり G に e を追加したとき閉路が作られてしまうかどうかを確かめる方法はいろいろありますが、素集合データ構造(Disjoint Set Union、Union-Find とも呼ばれる)を用いて判定するのがおすすめです。ここでは詳しくは解説しませんが、興味のある人は調べてみてください。
2-opt 法(Sランク相当)
2-opt 法は、巡回路を適当に作ってからその巡回路を更新し続けることによって解の精度を改善していくアルゴリズムです。
ここでいう更新とは、巡回路の辺を 2 本選んでつなぎ変えることを指します。つなぎ変えることによって解がよくなるならつなぎ変える、よくならないならつなぎ変えない、という操作を繰り返します。
たとえば、下図では dist(a, d) + dist(b, c) > dist(a, b) + dist(c, d) が成り立つため、辺をつなぎ変えます。

辺をつなぎ変える処理の実装が煩雑に感じる方がいらっしゃるかもしれませんが、実際は簡単に実装することができます。
巡回路 0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 0 の辺 1 -> 2 と辺 4 -> 5 をつなぎ変えると 0 -> 1 -> 4 -> 3 -> 2 -> 5 -> 0 となりますが、よく見るとこれは巡回路の 2 -> 3 -> 4 の部分を逆順にしたものになっていますから、巡回路の一部分を逆順にする処理を実装することで、辺のつなぎ変えをおこなうことができます。
辺をつなぎ変える練習問題はこちらの「辺の交換」(Aランク相当)で公開していますので、2-opt 法を実装する前に取り組んでみてください。
禁断探索法(Sランク相当)
禁断探索法は、2-opt 法と同じく初期解を適当に作ってからその解を更新し続けることによって解の精度を改善していくアルゴリズムです。
禁断探索法では禁断リストと呼ばれるリストを用いて、探索済みの解にすぐ戻ってしまうことを防いでいます。禁断探索法は多くの最適化問題に対して適用できるアルゴリズムで、禁断探索法を巡回セールスマン問題に対してどのように適用するかについてはさまざまなバリエーションが存在します。
巡回セールスマン問題メニューで実装する禁断探索法のアルゴリズムは、以下のようなものです。
- 巡回路を適当に作り、初期解 X とする。最良解 B を X で初期化する。禁断リストを空で初期化する。禁断リストのサイズの上限 TL を決める
- 一定の回数、以下を繰り返す
- (*) 巡回路 X を少しだけ変更したもの (X の近傍) であって、なおかつ禁断リストに含まれていない解のうち最も良い解 X' を求め、X を X' で更新する。X が B より真に良い場合は、B を X で更新する。解 X を禁断リストの先頭に加える。禁断リストのサイズが TL を超えた場合は禁断リストに含まれている最も古い解を削除する
- 最良解 B を解として出力する
解の履歴を一定期間保存する禁断リストを保持しておき、そのリストに含まれる解へ更新することを避けることで、探索が繰り返されてしまうことを防いでいます。
禁断リストに解(巡回路)そのものを記録するのはメモリ使用量の面から考えると大変なので、ここでは解の代わりに「つなぎ変えた辺の端点のうち巡回路 X の先頭に最も近い都市 t」を入れることにしています。つまり、都市 t を端点として持つ辺をつなぎ変えて解を更新したあとしばらくは、t を端点として持つ辺はつなぎ変えないということです。
禁断リストの実装には、キューを用いるのがおすすめです。キューについては「スタック・キューメニュー」で詳しく解説していますので興味のある方は見てみてください。
焼きなまし法(Sランク相当)
焼きなまし法は、2-opt 法と同じく初期解を適当に作ってからその解を更新し続けることによって解の精度を改善していくアルゴリズムです。
焼きなまし法では、仮想的な温度 T を用いて解を更新していきます。焼きなまし法は多くの最適化問題に対して適用できるアルゴリズムで、焼きなまし法を巡回セールスマン問題メニューに対してどのように適用するかについてはさまざまなバリエーションが存在します。
巡回セールスマン問題メニューで実装する焼きなまし法のアルゴリズムは、以下のようなものです。
- 巡回路を適当に作り、初期解とする
- 仮想的な温度 T を設定する
- 温度 T を受け取り 0 以上 1 以下の実数を返す関数 P を用意する。P は T が大きければ 1 に近い値を、小さければ 0 に近い値を返すように設計する
- 温度 T がある程度下がるまで以下を繰り返す
- (*) 巡回路を成す辺を 2 本選び、その辺をつなぎ変えることを考える。つなぎ変えることによって巡回路長が短くなるならつなぎ変える。短くならないなら、確率 P(T) でつなぎ変える。最後に温度 T を少し下げる
- 巡回路を出力する
アルゴリズムの最初の方では温度 T が高いため、悪くなってしまう場合であっても解を更新する確率が高くなります。つまり、アルゴリズムの初期段階では解が大胆に変わることが多くなります。
アルゴリズムの実行が進み温度 T が低くなっていくと、よくなる場合でないと滅多に更新されなくなっていきます。
このようにすることで、解が局所的最適解に留まってしまうことが防がれ、大域的最適解へと近づいていくことが期待できます。ただし、期待ができるというだけで、必ず大域的最適解に辿り着く保証があるというわけではないため注意が必要です。
巡回セールスマン問題の楽しい応用例
ここまで読んで、問題を解いてくださった方の中には、「巡回セールスマン問題って難しいなぁ……」という印象を持たれた方も多いですよね。
ただ、以下の記事のように「アルゴリズムを使って効率よく飲食店のスタンプラリーに挑戦し、1年分の無料券をゲットする」といった応用例もあります。(実際にpaizaの社員が挑戦した記録です)
このようにアルゴリズムを使いこなせれば、実生活で役に立つ場面もある……かもしれません!
まとめ
今回は、巡回セールスマン問題を解く多様なアルゴリズムを駆け足で紹介しました。
実装量が多くなかなか大変ですが、本記事の解説を参考にしながら根気よく取り組んでみてください。
また、paizaラーニングの学習講座「アルゴリズム入門編:「巡回セールスマン問題」を学ぶ」では、アルゴリズム初学者の方でも理解しやすいよう、もう少し噛み砕いて動画で解説しています。こちらも合わせてご活用ください。

「paizaラーニング」では、未経験者でもブラウザさえあれば、今すぐプログラミングの基礎が動画で学べるレッスンを多数公開しております。
詳しくはこちら

そしてpaizaでは、Webサービス開発企業などで求められるコーディング力や、テストケースを想定する力などが問われるプログラミングスキルチェック問題も提供しています。
スキルチェックに挑戦した人は、その結果によってS・A・B・C・D・Eの6段階のランクを取得できます。必要なスキルランクを取得すれば、書類選考なしで企業の求人に応募することも可能です。「自分のプログラミングスキルを客観的に知りたい」「スキルを使って転職したい」という方は、ぜひチャレンジしてみてください。
詳しくはこちら


